【完全ガイド】AWS Redshiftで始めるクラウドデータウェアハウス運用とSQL活用術

目次
- AWS Redshiftとは?
- アーキテクチャ概要
- 初期セットアップ手順
- SQL構文と実用サンプル
- パフォーマンス最適化
- 他サービスとの連携(ETL/BI)
- セキュリティとガバナンス
- ベストプラクティスと落とし穴
- よくある質問(FAQ)
- まとめ
はじめに
AWS Redshift(アマゾン・レッドシフト)は、Amazon Web Services(AWS)が提供する完全マネージド型のクラウドデータウェアハウス(DWH)サービスです。オンプレミスのDWHに代わる高パフォーマンスな分析基盤として、近年急速に導入が進んでいます。
本記事では、AWS Redshiftの基本構造から、高速なクエリ実行のためのSQLチューニング、ETL連携、BIツールとの接続まで、実務で即戦力となるノウハウを徹底解説します。
AWS Redshiftとは?
AWS Redshiftは、PB(ペタバイト)級のデータを高速で分析できる分散型DWHです。RedshiftはPostgreSQLに準拠しており、既存のSQL資産をそのまま活用可能。列指向ストレージとMPP(Massively Parallel Processing)アーキテクチャによって、大量データでも高速処理が可能です。
主な特徴
- 完全マネージド型(インフラ管理不要)
- 自動スケーリング(RA3ノードなど)
- クエリ高速化(Result Caching、Concurrency Scaling)
- Redshift SpectrumでS3データも直接分析可能
アーキテクチャ概要
Redshiftの基本構成は以下のようになっています。
- リーダーノード:クライアントと接続し、クエリを受け取って最適化
- コンピュートノード:実際のデータ処理を行う(複数のスライスに分割)
Redshiftは以下のように並列処理を前提とした設計になっており、JOINやGROUP BY、ウィンドウ関数なども高速処理可能です。
初期セットアップ手順
- AWSコンソールから「Redshift」を検索
- クラスターを作成(RA3インスタンス推奨)
- パラメータ設定(VPC, IAM Role)
- セキュリティグループでアクセス許可
- SQLクライアント(DBeaver, DataGrip, Redshift Query Editor)で接続
-- Redshiftクラスター作成後の初回接続確認
SELECT version();
SQL構文と実用サンプル
RedshiftはPostgreSQL互換のSQLを使用しますが、一部独自拡張もあります。
テーブル作成
CREATE TABLE sales (
sale_id BIGINT IDENTITY(1,1),
product_id INT,
sale_date DATE,
quantity INT,
price NUMERIC(10,2)
)
DISTSTYLE KEY
DISTKEY(product_id)
SORTKEY(sale_date);
DISTKEYとSORTKEYの適切な設定はクエリ性能に直結します。
以下は実際の作成画像です(DDL作成)
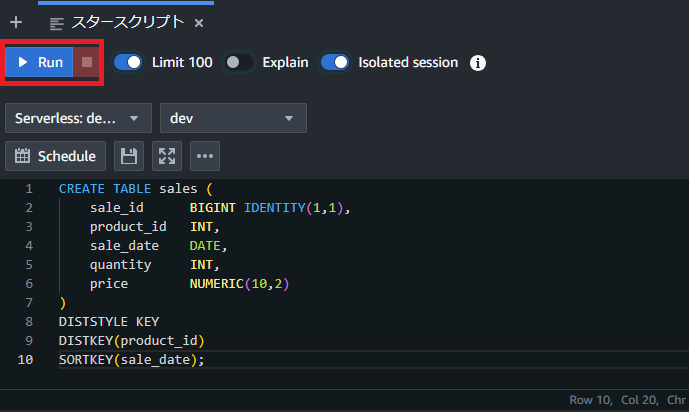
テーブルが作成されたか右クリックでRefreshをクリックします!
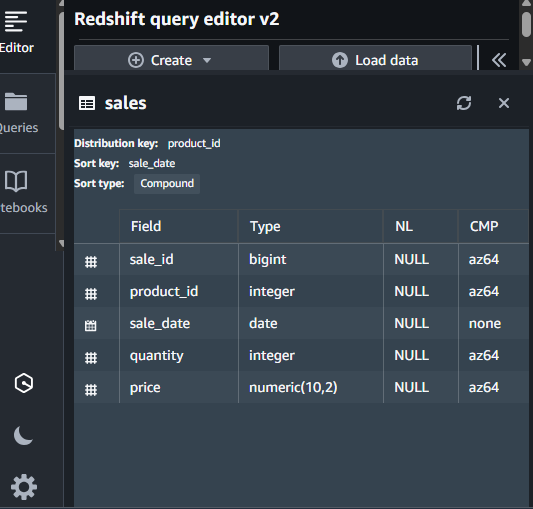
下記のようにテーブルが作成されています
データ投入
COPY sales
FROM 's3://your-bucket/sales.csv'
CREDENTIALS 'aws_iam_role=arn:aws:iam::xxxx:role/RedshiftRole'
CSV;
または下記のようにINSERTします
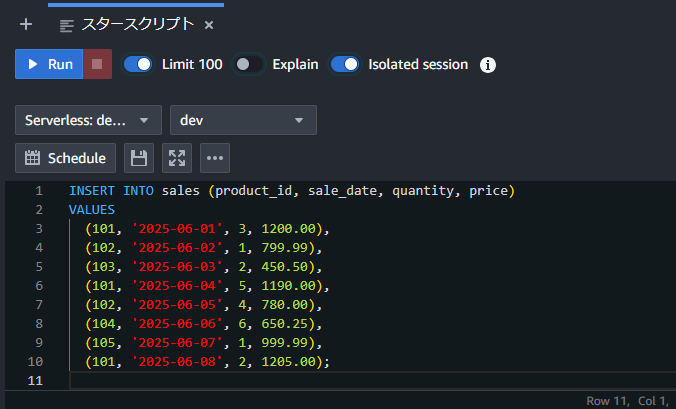
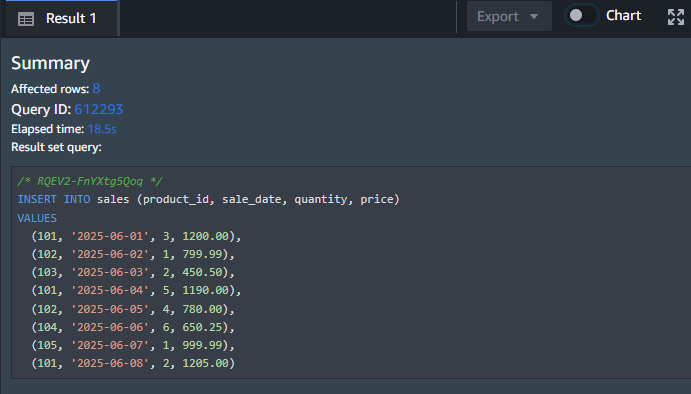
結果のイメージは下記になります
集計クエリ例(KPI作成)
SELECT
product_id,
DATE_TRUNC('month', sale_date) AS month,
SUM(quantity) AS total_quantity,
SUM(quantity * price) AS revenue
FROM sales
GROUP BY product_id, month
ORDER BY month DESC;
ウィンドウ関数(移動平均)
SELECT
product_id,
sale_date,
quantity,
AVG(quantity) OVER (PARTITION BY product_id ORDER BY sale_date ROWS BETWEEN 6 PRECEDING AND CURRENT ROW) AS moving_avg
FROM sales;
パフォーマンス最適化
Redshiftのクエリ最適化は設計・SQL両面で可能です。
チューニングポイント
- DISTKEY/SORTKEY設計:頻繁にJOIN・集計される列に設定
- 圧縮エンコーディング:
ANALYZE COMPRESSIONで最適化 - VACUUM/ANALYZE:定期的なテーブル整理
- Result Cache活用:同一クエリの再利用で高速化
- Concurrency Scaling:同時実行数増加時の自動リソース追加
-- 圧縮率確認
ANALYZE COMPRESSION sales;
他サービスとの連携(ETL/BI)
ETL連携(AWS Glue / dbt / Airflow)
RedshiftはGlueとシームレスに連携可能。ETL処理の自動化も簡単に構築可能。
-- Glue JobでRedshift → S3出力など可能
BIツール接続
- Amazon QuickSight
- Tableau
- Looker
- Power BI
Redshiftは標準JDBC/ODBCに対応しており、各種BIツールとの接続も容易です。
セキュリティとガバナンス
- IAMロールによるS3アクセス制御
- VPC内でのネットワーク制御
- Redshiftのデータ暗号化(at rest / in transit)
- Audit Logging(CloudTrail連携)
ベストプラクティスと落とし穴
よくある設計ミス
- DISTKEY未設定 → データ分散不均衡
- データロード後にVACUUM未実施 → クエリ低速化
- 巨大テーブルでUNLOADせず直接JOIN → OOM発生
ベストプラクティス
- 小規模クエリにはRedshift Serverlessも検討
- 頻繁にアクセスされるデータはMaterialized Viewでキャッシュ
- 必要に応じてRedshift SpectrumでS3直接クエリ
よくある質問(FAQ)
Q. Redshiftはリアルタイム分析に向いていますか?
Redshiftはバッチ処理に強く、リアルタイムにはKinesis + DynamoDBなどの方が適しています。Redshiftではマテビュー+リフレッシュで近リアルタイムも可能。
Q. データが増えすぎて遅くなったのですが?
まずはVACUUM、ANALYZE、DISTKEY/SORTKEY見直し。RA3インスタンスへのスケールアップも検討。
まとめ
AWS Redshiftは、スケーラブルかつ高速なデータ分析を実現するクラウドDWHです。SQLベースで操作でき、既存のデータエンジニアやアナリストも学習コストが低く、導入効果が高いのが魅力です。
構築時には、データの性質に合った設計(DISTKEY/SORTKEY)が極めて重要。また、日常運用でもVACUUMやモニタリングの自動化など、運用面での最適化を意識することが高性能維持のカギです。
🔧 自社向け導入・設計・運用のご相談はこちら
弊社では、AWS Redshiftを活用したデータ分析基盤構築支援を行っております。要件定義からETL・BI連携まで、ワンストップでサポート可能です。
お問い合わせ:[会社のお問い合わせフォーム]